@ttscoff , I have a general nerdery question for you. As the esteemed developer of Marked, which amazingly can preview Scrivener documents so well, you might have some wonderful insight to share.
This goes back to my (never-ending) quest to create the best way to work on longform Quarto documents. A Quarto “Book” project has a hierarchy of folders and documents. The structure matters less than one might think, because the _quarto.yml configuration file will specify the organization of the Book (into “parts”, “chapters”, and “appendices”). Nevertheless, it is common when editing a Quarto Book to create a hierarchy of folders (so you keep your sanity managing dozens of text documents).
I am wondering whether I can write my longform Quarto projects in Scrivener (with all the power tools available to me there), and then compile the contents into essentially a hierarchy of folders and files that is set up as the perfect starting point for the quarto render --to=pdf command to assemble the Book.
The challenge before me is this: How can I use Scrivener’s existing Binder structure to dynamically
- create the hierarchy of nested folders that organize the files,
- deposit the compiled Markdown documents into the right place, and
- populate the
_quarto.ymlconfiguration file with the relative file paths to these parts/chapters/appendices?
Here’s an example of a hypothetical Binder structure:
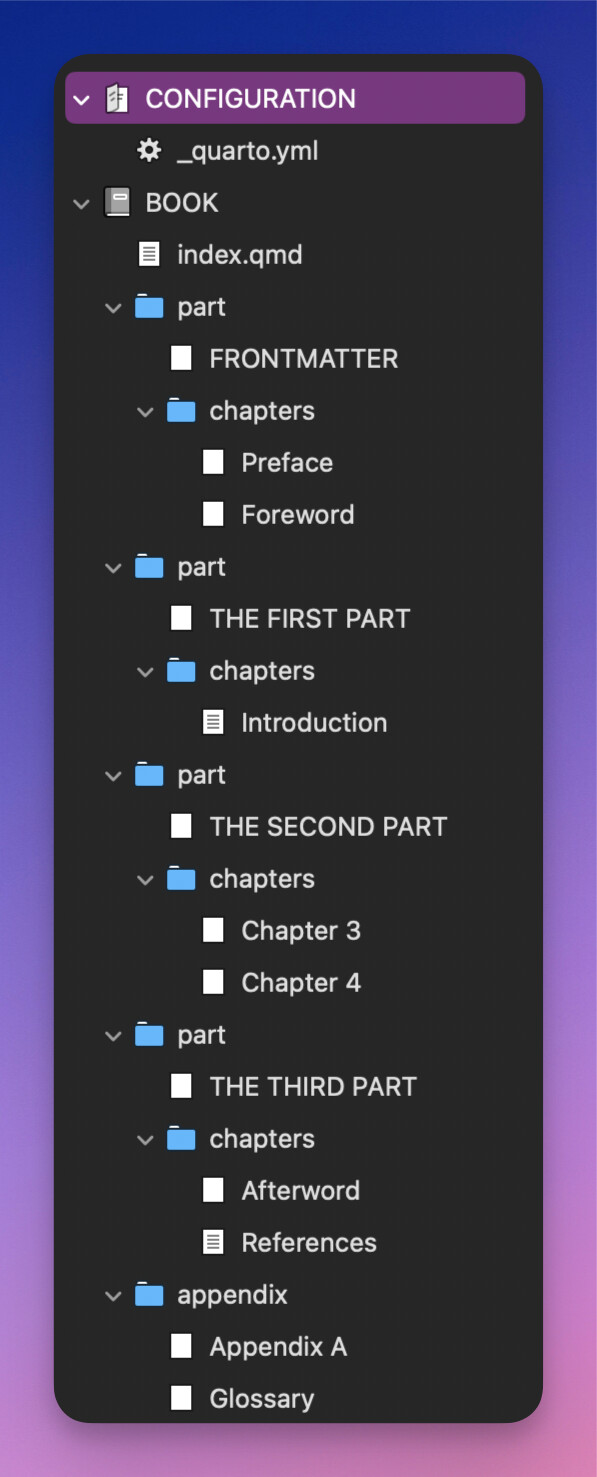
The folder tree that needs to be created would be something like this:
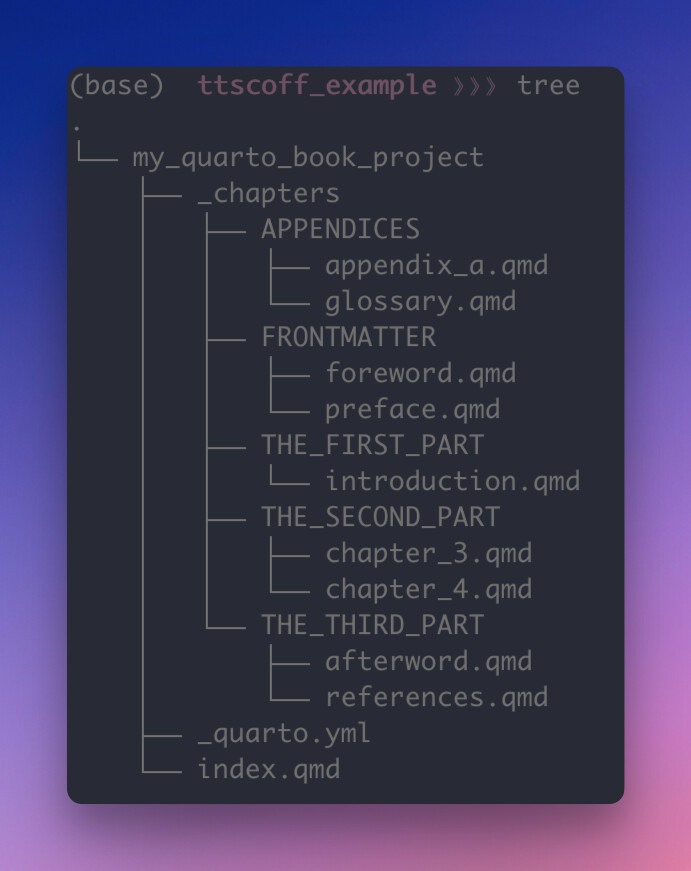
And a _quarto.yml file will need to be created to specify the hierarchical structure inputted there with file paths, e.g.,
# This file starts out with the options contained in the _quarto.yml document in Scrivener's Binder...
project:
type: book
book:
title: "My Quarto Book Project"
subtitle: "Hypothetical Example of a Quarto Book from Scrivener"
author: "cavalierex"
date: last-modified
# The following chapter and appendix listing is what gets injected dynamically from the Binder structure...
chapters:
- index.qmd
- part: "FRONTMATTER"
chapters:
- _chapters/FRONTMATTER/preface.qmd
- _chapters/FRONTMATTER/foreword.qmd
- part: "THE FIRST PART"
chapters:
- _chapters/THE_FIRST_PART/introduction.qmd
- part: "THE SECOND PART"
chapters:
- _chapters/THE_SECOND_PART/chapter_3.qmd
- _chapters/THE_SECOND_PART/chapter_4.qmd
- part: "THE THIRD PART"
chapters:
- _chapters/THE_THIRD_PART/afterword.qmd
- _chapters/THE_THIRD_PART/references.qmd
appendices:
- _chapters/APPENDICES/appendix_a.qmd
- _chapters/APPENDICES/glossary.qmd
# and back to specifying the other options contained in the _quarto.yml document in Scrivener's Binder...
So, with that longwinded introduction over, my question for you is: What is the approach that you used in Marked to preview the nested hierarchical Binder structure to show all the documents? And what advice would you give for an approach to creating the nested hierarchy of folders/files as well as dynamically entering the path list into the _quarto.yml file?
(Respectfully, I am not asking you to solve the problem for me, nor do I expect you to necessarily figure out the Scrivener “compile” side of things. I am simply looking for advice re: how to exploit the power of the Binder to create the starting point for a Quarto Book project, which is essentially nested folders and files.)
I appreciate your time and advice!!
–Alexander.
PS> For what it’s worth, Python would likely be my tool of choice.